Research Everything IT








RECENTLY ADDED
Read the Latest in the Research Hub


Jan 30, 2026
Security

5 IAM Trends to Watch in 2026 (and How to Prepare for Them)
Article
5 min
In 2026, identity security is a discipline, not a product stack. It’s more important than ever to secure people, machines and AI agents alike by clarifying controls, accounting for nonhuman identities and focusing on practical metrics.

Jan 30, 2026
Data Center

All-Flash Arrays (AFAs): Everything You Need To Know
Article
13 min
Learn about all-flash array architecture, performance metrics and vendor selection criteria to maximize ROI and modernize your storage infrastructure.

Jan 29, 2026
Security
FETC 2026: How K–12 Districts Can Build a Mature Cybersecurity Architecture
Article
3 min
Schools should treat cybersecurity as a shared culture grounded in clear frameworks, coherent architecture, continuous assessment and trusted partnerships.

Jan 21, 2026
Data Center

Why AI Demand Is Reshaping the Memory Market
Article
2 min
AI demand is reshaping global memory supply, driving pricing and availability challenges across devices and infrastructure. Learn what signals matter most and how IT leaders can plan early to manage volatility and protect budgets.

Jan 20, 2026
AI and Emerging Tech
6 Data Trends That Will Determine Your AI Future
Article
4 min
Will you have AI success in 2026? Learn why strong data foundations, not just advanced models, determine whether your enterprise scales or stalls.

Jan 13, 2026
Networking
Challenged by a Network Upgrade? Help Is On the Way
Article
3 min
CDW services bolster the efforts of in-house IT teams as organizations deploy new technologies to provide users with better services.
TRENDING
What Other IT Pros are Researching
View All
Sep 16, 2022
Networking

Why You Should Consider an Upgrade to Wi-Fi 6 or 6e
article
3 min
A wireless upgrade can help organizations meet users’ growing demand for connectivity.
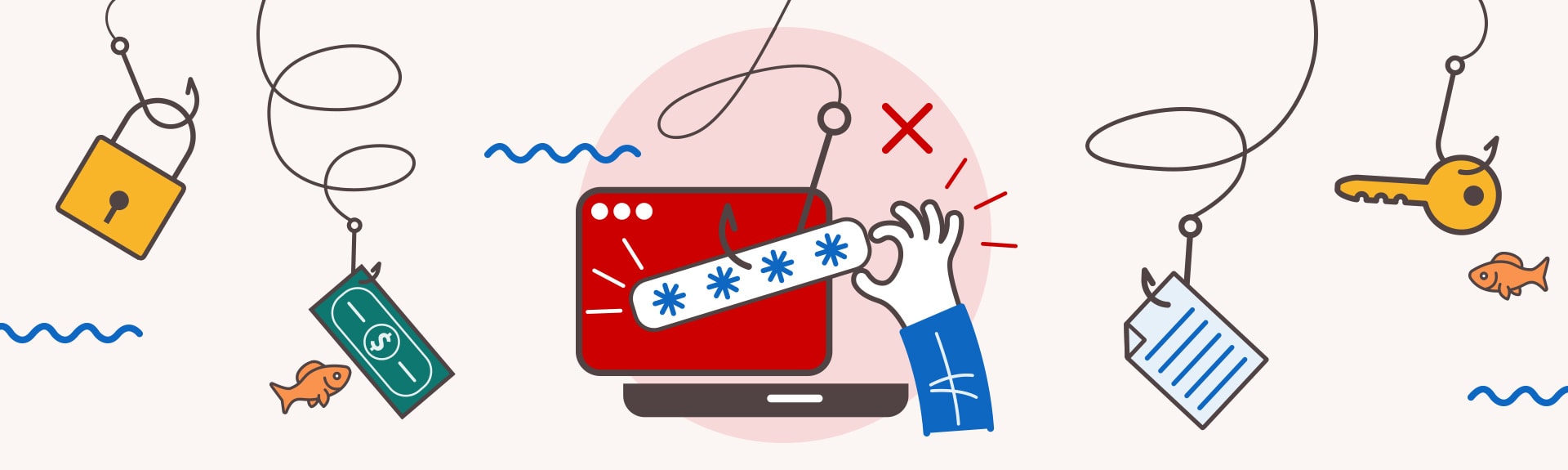
Oct 03, 2022
Security
Don't Get Hooked: Avoid Becoming the Bait of a Phishing Email
article
3 min
Take a look at this infographic to learn what to look out for in a suspicious email.

Sep 23, 2022
Digital Workspace
Conversation Design Puts AI One Step Closer to Humans
article
4 min
Conversation interfaces can enable customer interaction with automated systems more naturally.

Sep 09, 2022
Cloud
When a DDoS attack comes, defend your applications with an AWS firewall
article
3 min
CDW Managed Services for AWS protects customer web applications using AWS WAF Security Automations.
SECURITY
Create a Secure Digital Environment
Helping to protect you—and your end users—from security breaches.
Jan 30, 2026
Security
5 IAM Trends to Watch in 2026 (and How to Prepare for Them)
Article
5 min
In 2026, identity security is a discipline, not a product stack. It’s more important than ever to secure people, machines and AI agents alike by clarifying controls, accounting for nonhuman identities and focusing on practical metrics.
Jan 29, 2026
Security
FETC 2026: How K–12 Districts Can Build a Mature Cybersecurity Architecture
Article
3 min
Schools should treat cybersecurity as a shared culture grounded in clear frameworks, coherent architecture, continuous assessment and trusted partnerships.

Dec 23, 2025
Security

How Businesses Can Enhance Security and Deployments in Multi-OS Environments
Use Case
3 min
Discover how CDW helped a leading financial services company optimize device performance and streamline deployments within a mixed Windows and Mac ecosystem.

Dec 17, 2025
Security

How Businesses Can Enhance Security for Legacy Applications
Case Study
3 min
Discover how CDW helped a rural insurance provider modernize access for a legacy application that lacked support for current authentication methods.


Accelerate productivity and security with AI-driven PCs powered by Windows 11 Pro and Intel® CoreTM Ultra processors.


Palo Alto Networks enables cyber transformation with best-of-breed network and security solutions, world-class threat intelligence and expert services.

Check Point CloudGuard offers unified cloud native security across your applications, workloads, and network.


A proven security platform that is data-centric, cloud-smart, and as fast as your organization.


Prioritize student wellbeing and ensure students stay safe, secure, and ready to learn with Securly's Student Wellness Solution.

Get Improved Endpoint Protection – and More ROI – with Symantec SMART Security Solutions


Capture Client endpoint protection provides security against the latest threats no matter where the endpoint sits.
Collaboration
A Digital Workspace for New Ways of Working
View All
Dec 23, 2025
Digital Workspace
Empowering Hybrid Collaboration: Logitech Solutions for the Modern Workplace
Article
3 min
Logitech has led the way with technology innovations that support modern workers in a variety of work environments.

Dec 15, 2025
Digital Workspace

Why Culture, Not Code, Determines AI Success
Article
5 min
AI succeeds when organizations focus on people, not mandates. Explore how to drive adoption with clear goals, strong governance and pilot-led experimentation that delivers real business outcomes.

Dec 12, 2025
Digital Workspace
Four Trends to Watch in 2026 as Workplace Technology Evolves
Video
3 min
By leaning into these new developments, organizations can set themselves up for success.

Dec 09, 2025
Digital Workspace

How To Modernize Your Customer Contact Center To Meet Evolving Expectations
Article
5 min
AI-enhanced platforms, customer contact centers are rapidly evolving to make agents more productive and to provide a seamless customer experience.
CLOUD
Complete Your Cloud Journey

Dec 31, 2025
Cloud
Optimizing Public Sector IT Environments
Article
3 min
A careful look at existing resources can free up considerable cash for new technology investments.

Dec 22, 2025
Cloud
How to Maximize Microsoft CSP and Unlock AI Success With CDW
Webinar
2 min
Discover how CDW helps maximize Microsoft CSP with Copilot adoption, Azure optimization, Inscape insights and expert support

Dec 17, 2025
Cloud
4 Cloud Trends for 2026
Video
3 min
Organizations view the cloud as a foundation for automation and agility, leading them to focus on efficiency and optimization.

Dec 15, 2025
Cloud

How Agentic AI Is Shaping the Future of Platform Engineering
Article
4 min
Agentic AI is revolutionizing hybrid cloud migrations and platform engineering by automating complex workflows and improving developer experiences — driving resilient, innovative infrastructure with multi-agent collaboration and expert guidance.

Question: What saves you time, money & cybersecurity headaches? Answer: Trend Micro


RSA provides identity-first solutions for security-first organizations.

A proven security platform that is data-centric, cloud-smart, and as fast as your organization.


Add value to your work environment with high performance, portability, and secure LG mobile Thin Client solutions.


Bitdefender delivers comprehensive threat prevention, detection, and response solutions for all your security needs.

